- Vous n'avez pas de notification
![EasyHoster, Hébergeur cPanel & Hébergement WordPress : [Avocado] Incident 26 septembre 2025 - Downtime suite à un problème au datacenter](https://www.easyhoster.com/wp-content/uploads/2020/09/hebergement-web-premium.png)
[Lundi, 29/09] Retour du datacenter sur leurs interventions :
Suite à la réponse détaillée et transparente reçue ce lundi de l'équipe de communication de notre datacenter concernant l'interruption de service survenue la semaine dernière, nous tenons à en partager les éléments clés avec vous.
Le datacenter a qualifié cette indisponibilité prolongée d'inhabituelle et a fourni des explications détaillées sur ses causes : une succession de problèmes matériels (nécessitant un changement de connecteur électrique, un redémarrage d'un serveur non reconnecté au réseau, suivi d'une seconde intervention pour des vérifications approfondies), cumulés à d'autres incidents critiques de sévérité supérieure au sein du même datacenter.
Ces facteurs ont entraîné un manque de techniciens disponibles dans l'immédiat, particulièrement un vendredi soir.
Nous avons exprimé notre souhait d'une communication plus fluide lors de tels incidents, notamment pour confirmer le statut des interventions en temps réel. Ils ont confirmé être conscients de cette attente, partagée par d'autres clients, et ont pris note de notre feedback pour des améliorations futures.
Nous apprécions leur transparence et le faite qu'ils ont assumés leurs responsabilités. Cela renforcent notre confiance en un partenariat durable. Nous espérons ainsi poursuivre une collaboration sans incidents majeurs, tout en continuant à veiller à la fiabilité de nos services.
Merci encore pour votre compréhension.
Mise à jour / Communiqué suite à fin de l'intervention du datacenter :
Nous faisons suite à l’incident ayant engendré un délai d’interruption de votre service « Avocado » que nous qualifions tout comme vous d’inacceptable.
Mais comment justifier l’injustifiable ?
Comme vous le savez, EasyHoster emploie des fournisseurs, que cela soit pour ses solutions software comme cPanel, CloudLinux, JetBackup, etc., ou la location de serveurs aux datacenters.
Pour ce choix et après avoir testé de très nombreux fournisseurs, nous nous sommes arrêtés sur OVHcloud, comme vous avez peut-être pu le lire sur notre site. Selon nous, malgré les critiques qu’on peut lire concernant leurs services d’Hébergement Mutualisé, OVH offre généralement un excellent service en ce qui concerne les Serveurs Dédiés Bare Metal, avec des interventions physiques sous 30 minutes sur place au datacenter en cas d’incident matériel. Le tout avec une très bonne communication transparente lorsqu’un (rare) incident physique se produit… c’était en tout cas notre expérience depuis toutes ces années.
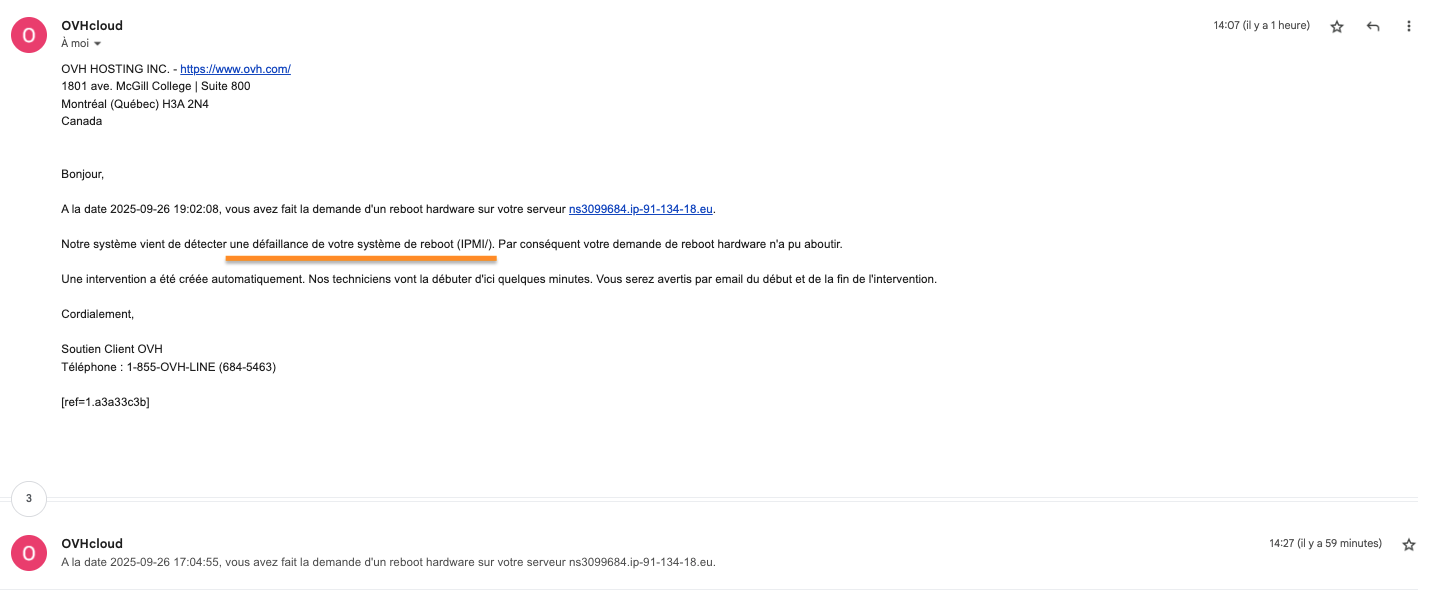
Hier soir, nous avons constaté tout comme vous une interruption du serveur Avocado sur lequel est hébergé votre service. Notre équipe a été informée de ce défaut dans les minutes suivant l’incident, notifiée grâce à nos différents services de monitoring.
Nous avons immédiatement vérifié le serveur et avons constaté que notre console de dépannage d’urgence (IPMI) n’était plus accessible. La perte de l’accès à IPMI démontre de manière certaine un problème au datacenter.
Dans ce genre de cas de figure, grâce au service de monitoring d’OVHcloud avec « intervention proactive », un technicien est généralement automatiquement averti du défaut sur le serveur et doit intervenir dans une moyenne d’environ 30 minutes pour vérifier l’état du matériel (le serveur et tout ce qui l’entoure).
Néanmoins, face à la nature de l’incident (perte d’accès IPMI), nous avons pris l’initiative de contacter OVHcloud sans délai via tous les canaux à notre disposition : chat, ticket, Twitter…
Nous avons reçu rapidement des réponses de leur part nous indiquant qu’une intervention de vérification était planifiée avec le plus haut niveau de priorité, bien que « les techniciens à Gravelines (où se situe ce datacenter) soient fort occupés ».
En parallèle, nous avons tenté de répondre aux dizaines de plaintes reçues de nombreux clients aussi désemparés que nous face à cette situation, malheureusement sans pouvoir leur fournir d’explication suffisamment détaillée et compréhensible.
À 02:12:23, nous voyons apparaître la mention « Electric connector » dans la liste des interventions d’OVHcloud concernant ce serveur et seulement à 07:28:35, nous voyons apparaître la mention « Netboot Update (rescue-techdc - Internal rescue for techDC diag) » qui indique qu’un technicien intervient (enfin) sur la machine pour vérifications.
Durant toute la nuit (pendant laquelle notre équipe n’a pas pu dormir, cela va de soi), nous n’avons cessé de relancer et relancer encore OVH via tous les canaux de communication, avec la volonté de faire tout ce qui était possible de notre côté pour augmenter la priorité de notre demande d’intervention.
Pendant ce temps, aucune info n’était disponible sur la page de status d’OVHcloud et tous les serveurs de la baie du serveur Avocado étaient marqués comme UP, ce qui n’est en soi pas normal puisque notre serveur était évidemment DOWN (IPMI compris).
À 08:07:23, soit 40 minutes après le début de l’intervention constatée, démarrée avec 14 heures de retard par rapport aux engagements d’OVHcloud, le serveur a été redémarré avec succès par un technicien qui ne nous a fourni aucune information, ni justification sur le défaut qui existait sur le serveur, ni sur le délai extrêmement plus long qu’à l’habitude pour l’intervention physique. Le rapport d’intervention (que nous jugeons très décevant) indiquait uniquement :
« Reboot HARD. Date 2025-09-27 07:27:54 CEST (UTC +02:00), Reboot HARD: Voici le détail de l'intervention réalisée: Pas d'information à l’écran ("écran noir"). Pas de réponse au clavier. Actions entreprises: Redémarrage hardware du serveur. Résultat: Boot OK. Serveur sur 'login'. Ping OK, services démarrés. HARD Reboot ».
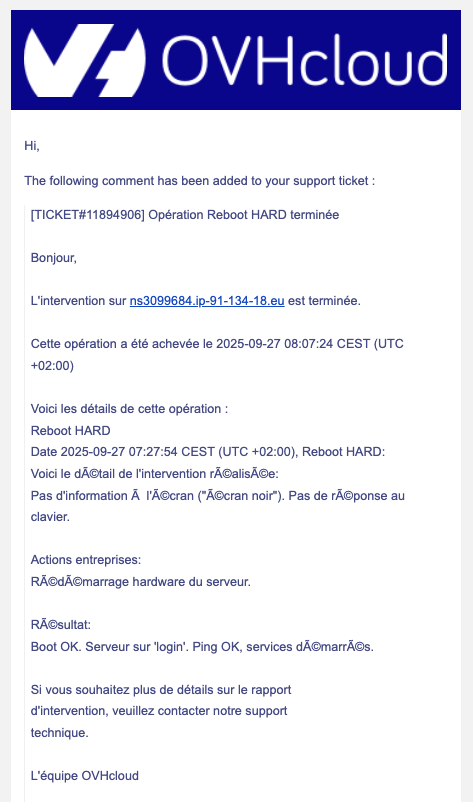
Autrement dit, le technicien d’OVHcloud semblait nous indiquer qu’un simple reboot aurait suffi à faire repartir la machine, alors que nous avons des journaux faisant mention de nombreuses tentatives de reboot tentées de notre côté qui ont toutes échoué et que l’accès à IPMI était impossible, preuve d’un souci plus profond côté hardware (et non uniquement de notre fait, côté software).
En complément, nous avons reçu avec un peu de retard une courte explication concernant l’entrée « Electric connector » présentée dans la liste d’interventions :
« Voici les détails de cette opération : Connectique électrique Date 2025-09-27 01:52:36 CEST (UTC +02:00), Connectique électrique: Votre serveur était éteint. Nous avons vérifié le bon fonctionnement du système de refroidissement ainsi que l'absence d'erreur hardware dans les logs. Nous avons redémarré votre serveur et suivi la phase de boot dans le cas où des erreurs seraient présentes. Votre serveur est sur l'écran de connexion ».

Malheureusement, aucune explication sur le délai d’intervention de vérification hardware largement supérieur à l’habitude.
Donc, que pouvons-nous vous dire à part que, tout comme vous, nous sommes déçus de la manière dont a été traité cet incident, autant pour le délai de remise en service que pour le manque de communication du datacenter durant tout ce temps d’interruption.
Néanmoins, nous devons aussi prendre en considération les années précédentes où nous avons bénéficié d’un excellent service pour tout besoin étant dans le scope d’OVHcloud.
C’est pourquoi nous espérons que la manière dont a été traité cet incident sera isolée et que nous retrouverons une meilleure expérience à l’avenir avec le datacenter que nous avons choisi en vue de vous offrir le meilleur service possible.
Dans cette optique, nous allons faire remonter notre insatisfaction à OVHcloud, en espérant que des mesures seront prises en interne pour améliorer le traitement des incidents hardware expérimentés au datacenter, ainsi que la communication entre le client et le datacenter.
Nous tenons à vous rappeler que vos données ont toujours été en sécurité, puisque régulièrement sauvegardées et décentralisées à 3 emplacements, dont 2 à l’étranger.
Nous tenons bien sûr aussi à vous exprimer nos plus profondes excuses pour cet événement indépendant des actions d’EasyHoster et tenons à vous rappeler notre engagement à vous offrir les meilleurs services qui soient en cherchant toujours à donner le meilleur dans tout le champ d’action où nous avons du contrôle.
Notre équipe reste comme toujours à votre entière disposition par ticket pour échanger et recevoir toute remarque que vous désireriez nous faire parvenir.
Merci infiniment pour votre confiance et compréhension.
______
Annonce originale :
Cher clients,
Nous tenons à vous informer que le serveur Avocado.easyhoster.com rencontre actuellement un problème technique du côté du datacenter. Le serveur est inaccessible depuis environ une heure, ce qui impacte certains de nos services.
Nous avons immédiatement contacté le support technique du datacenter, et une intervention est en cours de planification pour diagnostiquer et résoudre le souci le plus rapidement possible. Malheureusement, en raison d'une charge de travail élevée au datacenter, nous n'avons pas encore d'heure estimée de résolution, mais nous suivons l'évolution de près et vous tiendrons informés dès que nous aurons des nouvelles.
Nous nous excusons sincèrement pour les désagréments occasionnés indépendants de notre volonté et mettons tout en œuvre pour restaurer le service dans les meilleurs délais. Si vous avez des questions urgentes, n'hésitez pas à nous contacter via par ticket.
Merci pour votre patience et votre compréhension.
